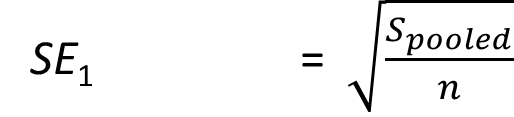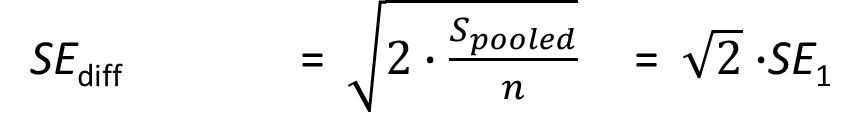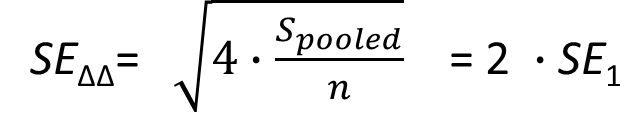ci.2x2.mean.bs() |
Computes tests and confidence intervals of effects in a 2x2 between-subjects design for means |
ci.2x2.mean.mixed() |
Computes tests and confidence intervals of effects in a 2x2 mixed design for means |
ci.2x2.mean.ws() |
Computes tests and confidence intervals of effects in a 2x2 within-subjects design for means |
ci.2x2.median.bs() |
Computes tests and confidence intervals of effects in a 2x2 between-subjects design for medians |
ci.2x2.median.mixed() |
Computes confidence intervals of effects in a 2x2 mixed design for medians |
ci.2x2.median.ws() |
Computes confidence intervals of effects in a 2x2 within-subjects design for medians |
ci.2x2.prop.bs() |
Computes tests and confidence intervals of effects in a 2x2 between- subjects design for proportions |
ci.2x2.prop.mixed() |
Computes tests and confidence intervals of effects in a 2x2 mixed factorial design for proportions |
ci.2x2.stdmean.bs() |
Computes confidence intervals of standardized effects in a 2x2 between-subjects design |
ci.2x2.stdmean.mixed() |
Computes confidence intervals of standardized effects in a 2x2 mixed design |
ci.2x2.stdmean.ws() |
Computes confidence intervals of standardized effects in a 2x2 within-subjects design |
ci.agree.3rater() |
Computes confidence intervals for a 3-rater design with dichotomous ratings |
ci.agree() |
Confidence interval for a G-index of agreement |
ci.agree2() |
Confidence interval for G-index difference in a 2-group design |
ci.bayes.normal() |
Bayesian credible interval for a normal prior distribution |
ci.bayes.prop() |
Bayesian credible interval for a proportion |
ci.biphi() |
Confidence interval for a biserial-phi correlation |
ci.bscor() |
Confidence interval for a biserial correlation |
ci.cod() |
Confidence interval for a coefficient of dispersion |
ci.condslope.log() |
Confidence intervals for conditional (simple) slopes in a logistic model |
ci.condslope() |
Confidence intervals for conditional (simple) slopes in a linear model |
ci.cor.dep() |
Confidence interval for a difference in dependent Pearson correlations |
ci.cor() |
Confidence interval for a Pearson or partial correlation |
ci.cor2.gen() |
Confidence interval for a 2-group correlation difference |
ci.cor2() |
Confidence interval for a 2-group Pearson correlation difference |
ci.cqv() |
Confidence interval for a coefficient of quartile variation |
ci.cramer() |
Confidence interval for Cramer’s V |
ci.cronbach() |
Confidence interval for a Cronbach reliability |
ci.cronbach2() |
Confidence interval for a difference in Cronbach reliabilities in a 2-group design |
ci.cv() |
Confidence interval for a coefficient of variation |
ci.etasqr() |
Confidence interval for eta-squared |
ci.fisher() |
Fisher confidence interval |
ci.indirect() |
Confidence interval for an indirect effect |
ci.kappa() |
Confidence interval for two kappa reliability coefficients |
ci.lc.gen.bs() |
Confidence interval for a linear contrast of parameters in a between-subjects design |
ci.lc.glm() |
Confidence interval for a linear contrast of general linear model parameters |
ci.lc.mean.bs() |
Confidence interval for a linear contrast of means in a between-subjects design |
ci.lc.median.bs() |
Confidence interval for a linear contrast of medians in a between-subjects design |
ci.lc.prop.bs() |
Confidence interval for a linear contrast of proportions in a between- subjects design |
ci.lc.reg() |
Confidence interval for a linear contrast of regression coefficients in multiple group regression model |
ci.lc.stdmean.bs() |
Confidence interval for a standardized linear contrast of means in a between-subjects design |
ci.lc.stdmean.ws() |
Confidence interval for a standardized linear contrast of means in a within-subjects design |
ci.mad() |
Confidence interval for a mean absolute deviation |
ci.mann() |
Confidence interval for a Mann-Whitney parameter |
ci.mape() |
Confidence interval for a mean absolute prediction error |
ci.mean.fpc() |
Confidence interval for a mean with a finite population correction |
ci.mean.ps() |
Confidence interval for a paired-samples mean difference |
ci.mean() ci.mean1() |
Confidence interval for a mean |
ci.mean2() |
Confidence interval for a 2-group mean difference |
ci.median.ps() |
Confidence interval for a paired-samples median difference |
ci.median() ci.median1() |
Confidence interval for a median |
ci.median2() |
Confidence interval for a 2-group median difference |
ci.oddsratio() |
Confidence interval for an odds ratio |
ci.pairs.mult() |
Confidence intervals for pairwise proportion differences of a multinomial variable |
ci.pairs.prop.bs() |
Bonferroni confidence intervals for all pairwise proportion differences in a between-subjects design |
ci.pbcor() |
Confidence intervals for point-biserial correlations |
ci.phi() |
Confidence interval for a phi correlation |
ci.poisson() |
Confidence interval for a Poisson rate |
ci.popsize() |
Confidence interval for an unknown population size |
ci.prop.fpc() |
Confidence interval for a proportion with a finite population correction |
ci.prop.inv() |
Confidence interval for a proportion using inverse sampling |
ci.prop.ps() |
Confidence interval for a paired-samples proportion difference |
ci.prop() ci.prop1() |
Confidence intervals for a proportion |
ci.prop2.inv() |
Confidence interval for a 2-group proportion difference using inverse sampling |
ci.prop2() |
Confidence interval for a 2-group proportion difference |
ci.pv() |
Confidence intervals for positive and negative predictive values with retrospective sampling |
ci.random.anova() |
Confidence intervals for parameters of one-way random effects ANOVA |
ci.ratio.cod2() |
Confidence interval for a ratio of dispersion coefficients in a 2-group design |
ci.ratio.cv2() |
Confidence interval for a ratio of coefficients of variation in a 2-group design |
ci.ratio.mad.ps() |
Confidence interval for a paired-sample MAD ratio |
ci.ratio.mad2() |
Confidence interval for a 2-group ratio of mean absolute deviations |
ci.ratio.mape2() |
Confidence interval for a ratio of mean absolute prediction errors in a 2-group design |
ci.ratio.mean.ps() |
Confidence interval for a paired-samples mean ratio |
ci.ratio.mean2() |
Confidence interval for a 2-group mean ratio |
ci.ratio.median.ps() |
Confidence interval for a paired-samples median ratio |
ci.ratio.median2() |
Confidence interval for a 2-group median ratio |
ci.ratio.poisson2() |
Confidence interval for a ratio of Poisson rates in a 2-group design |
ci.ratio.prop.ps() |
Confidence interval for a paired-samples proportion ratio |
ci.ratio.prop2() |
Confidence interval for a 2-group proportion ratio |
ci.ratio.sd2() |
Confidence interval for a 2-group ratio of standard deviations |
ci.rel2() |
Confidence interval for a 2-group reliability difference |
ci.reliability() |
Confidence interval for a reliability coefficient |
ci.rsqr() |
Confidence interval for squared multiple correlation |
ci.sign() |
Confidence interval for the parameter of the one-sample sign test |
ci.slope.mean.bs() |
Confidence interval for the slope of means in a one-factor experimental design with a quantitative between-subjects factor |
ci.slope.prop.bs() |
Confidence interval for a slope of a proportion in a single-factor experimental design with a quantitative between-subjects factor |
ci.spcor() |
Confidence interval for a semipartial correlation |
ci.spear() |
Confidence interval for a Spearman correlation |
ci.spear2() |
Confidence interval for a 2-group Spearman correlation difference |
ci.stdmean.ps() |
Confidence intervals for a paired-samples standardized mean difference |
ci.stdmean() ci.stdmean1() |
Confidence interval for a standardized mean |
ci.stdmean.strat() |
Confidence intervals for a 2-group standardized mean difference with stratified sampling |
ci.stdmean2() |
Confidence intervals for a 2-group standardized mean difference |
ci.tetra() |
Confidence interval for a tetrachoric correlation |
ci.theil() |
Theil-Sen estimate and confidence interval for slope |
ci.tukey() |
Tukey-Kramer confidence intervals for all pairwise mean differences in a between-subjects design |
ci.var.upper() |
Upper confidence limit of a variance |
ci.yule() |
Confidence intervals for generalized Yule coefficients |